Chapter11. 객체 관계형 매핑을 통한 데이터
- 객체 관계형 매핑 - ORM(Object-Relational Mapping)
- 관계 모델과 객체 모델을 연결
- 장점
- 코드 양과 개발 시간을 단축할 수 있다.
- 오류가 발생하기 쉬운 SQL 코드 작성을 하지 않아도 된다.
- 특징
- 지연 로딩(lazy loading)
- 객체의 프로퍼티 중 실제로 필요한 프로퍼티만 가져올 수 있다.
- 조기 인출(eager fetching)
- 객체의 프로퍼티를 단 한번의 연산으로 모두 가져올 수 있다.
- 캐스케이딩(cascading)
- 테이블의 변경에 따라 영향을 받는 여러 테이블을 한꺼번에 변경할 수 있다.
- 지연 로딩(lazy loading)
- 프레임워크들
- 하이버네이트, iBATIS, Apache OJB, JDO, Oracle TopLink, JPA 등
- 스프링에서 JDBC는 잘 작동하지만, 복잡한 어플리케이션의 객체지향 요구 사항을 매끄럽게 따르기 위해 ORM을 사용한다.
11.1 스프링과 하이버네이트 통합
11.1.1 하이버네이트 세션 팩토리 선언
Session과 SessionFactory
Session: 저장, 업데이트, 삭제 등의 기본적인 데이터 접근 기능을 제공한다.
Session session = sessionFactory.openSession(); session.beginTransaction(); session.save( new Event( "Our very first event!", new Date() ) ); session.save( new Event( "A follow up event", new Date() ) ); session.getTransaction().commit(); session.close();SessionFactory: Session 객체들을 관리한다.
StandardServiceRegistry standardRegistry = new StandardServiceRegistryBuilder() .configure( "org/hibernate/example/hibernate.cfg.xml" ) .build(); Metadata metadata = new MetadataSources( standardRegistry ) .addAnnotatedClass( MyEntity.class ) .addAnnotatedClassName( "org.hibernate.example.Customer" ) .addResource( "org/hibernate/example/Order.hbm.xml" ) .addResource( "org/hibernate/example/Product.orm.xml" ) .getMetadataBuilder() .applyImplicitNamingStrategy( ImplicitNamingStrategyJpaCompliantImpl.INSTANCE ) .build(); SessionFactory sessionFactory = metadata.getSessionFactoryBuilder() .applyBeanManager( getBeanManager() ) .build();- 참고: Hibernate ORM User Guide (http://docs.jboss.org/hibernate/orm/5.2/userguide/html_single/Hibernate_User_Guide.html#bootstrap-jpa)
스프링에서 SessionFactory 가져오기
XML : LocalSessionFactoryBean을 사용한다.
@Bean public LocalSessionFactoryBean sessionFactory(DataSource dataSource) { LocalSessionFactoryBean sfb = new LocalSessionFactoryBean(); sfb.setDataSource(dataSource); sfb.setMappingResources(new String[] { "Spitter.hbm.xml" }); // 버전 4이상 annotation: sfb.setPackagesToScan(new String[] { "com.habuma.spittr.domain" }); ... return sfb; }hbm.xml 예제
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD//EN" "http://www.hibernate.org/dtd/hibernate-mapping-3.0.dtd"> <hibernate-mapping> <class name="Employee" table="EMPLOYEE"> <meta attribute="class-description"> This class contains the employee detail. </meta> <id name="id" type="int" column="id"> <generator class="native"/> </id> <property name="firstName" column="first_name" type="string"/> <property name="lastName" column="last_name" type="string"/> <property name="salary" column="salary" type="int"/> </class> </hibernate-mapping>
Annotation
- 버전 3: AnnotationSessionFactoryBean을 사용한다.
버전 4: LocalSessionFactoryBean을 사용한다.
@Bean public AnnotationSessionFactoryBean sessionFactory(DataSource dataSource) { AnnotationSessionFactoryBean sfb = new AnnotationSessionFactoryBean(); sfb.setDataSource(dataSource); sfb.setPackagesToScan(new String[] { "com.habuma.spittr.domain" }); ... return sfb; }setPackagesToScan에 준 패키지안에서 @Entity나 @MappedSuperclass 등의 annotation을 찾는다.
- Entity 예제
@Entity public class Employee { @Id private int id; private String firstName; private String lastName; private int salary; }
- Entity 예제
클래스가 적을 때는 setAnnotatedClasses를 이용해 도메인 클래스를 나열할 수 있다.
sfb.setAnnotatedClasses(new Class<?>[] { Spitter.class, Spittle.class });
11.1.2 스프링으로부터 해방된 하이버네이트 구성
예전에는 스프링의 HibernateTemplate를 사용하도록 저장소 클래스를 만들었다.
예제
public class ProductDaoImpl implements ProductDao { private HibernateTemplate hibernateTemplate; public void setSessionFactory(SessionFactory sessionFactory) { this.hibernateTemplate = new HibernateTemplate(sessionFactory); } public Collection loadProductsByCategory(final String category) throws DataAccessException { return this.hibernateTemplate.execute(new HibernateCallback() { public Object doInHibernate(Session session) { Criteria criteria = session.createCriteria(Product.class); criteria.add(Expression.eq("category", category)); criteria.setMaxResults(6); return criteria.list(); } }; } }
요즘은 HibernateTemplate을 쓰지 않고 직접 저장소 클래스 안에서 SessionFactory를 와이어링한다.
- 스프링과 분리된 하이버네이트 저장소를 구현할 수 있다.
- 하이버네이트에 특화된 예외를 스프링의 예외로 변환화는 방법
- PersistenceExceptionTranslationPostProcessor 빈을 만든다.
- 이 빈은 @Repository가 적용된 모든 빈의 플랫폼에 특화된 예외를 스프링의 예외로 변환한다.
11.2 스프링과 자바 퍼시스턴스 API
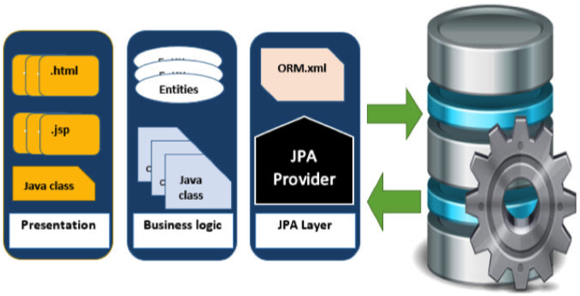
- JPA
- 차세대 자바 퍼시스턴스 표준!
- POJO 기반의 퍼시스턴스 메카니즘
The Java Persistence API (JPA) is a Java application programming interface specification that describes the management of relational data in applications using Java Platform, Standard Edition and Java Platform, Enterprise Edition.
Motivation
Prior to the introduction of EJB 3.0 specification, many enterprise Java developers used lightweight persistent objects, provided by either persistence frameworks (for example Hibernate) or data access objects instead of entity beans. This is because entity beans, in previous EJB specifications, called for too much complicated code and heavy resource footprint, and they could be used only in Java EE application servers because of interconnections and dependencies in the source code between beans and DAO objects or persistence framework. Thus, many of the features originally presented in third-party persistence frameworks were incorporated into the Java Persistence API, and, as of 2006, projects like Hibernate (version 3.2) and TopLink Essentials have become themselves implementations of the Java Persistence API specification.
11.2.1 엔티티 관리자 팩토리 설정
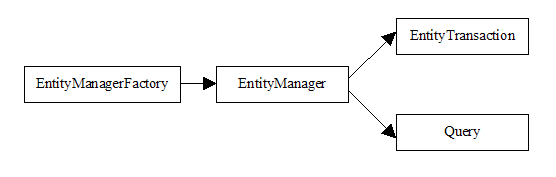
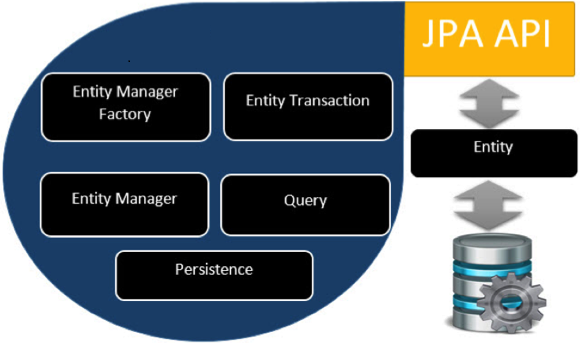
- EntityManager의 두가지 유형
- Application-managed
- 어플리케이션이
직접엔티티 관리자를 요청함으로써 엔티티 관리자가 생성되는 유형 - 직접 엔티티관리자를 다뤄야하며 트랜잭션처리까지 직접 책임
- Container-managed
- 자바 ee 컨테이너에 의해 생성되고 관리(
책임)되는 엔티티 관리자 - 어플리케이션이 직접 엔티티관리자와 상호작용하지 않고 객체주입같은 방식으로 획득하는 방식
즉, EntityManager가 생성되고 관리는 방식 차이 하지만 어차피 Spring이 EntityManager를 관리하고 책임지어 준다. 스프링은 위 유형에 대응하는 Factory빈을 갖추고 있어서 적절하게 엔티티관리자 팩토리를 생성한다.
Entity Factory Bean
- LocalEntityManagerFactoryBean - 어플리케이션 관리형
- LocalContainerEntityManagerFactoryBean - 컨테이너 관리형
스프링 입장에서는 두 방식의 차이점이라면 스프링 어플리케이션 컨텍스트에서 설정하는 방법뿐
어플리케이션 관리형 JPA 구성하기
- persistence.xml
- 퍼시스턴스 클래스와 데이터 소스 정보, 매핑 파일 이름과 같은 기본적인 메타 데이터 설정 정보를 기술
persistence.xml
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd"
version="2.0">
<persistence-unit name="org.hibernate.tutorial.jpa" transaction-type="RESOURCE_LOCAL">
<description>
Persistence unit for the JPA tutorial of the Hibernate Getting Started Guide
</description>
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<class>org.halyph.sessiondemo.Event</class>
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/jpatestdb" />
<property name="javax.persistence.jdbc.user" value="root" />
<property name="javax.persistence.jdbc.password" value="root" />
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQLDialect" />
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
</persistence-unit>
</persistence>
Bean 설정
@Bean
public LocalEntityManagerFactoryBean entityManagerFactoryBean() {
LocalEntityManagerFactoryBean emfb = new LocalEntityManagerFactoryBean();
emfb.setPersistenceUnitName("org.hibernate.tutorial.jpa");
return emfb;
}
- persistece.xml로 빼놓음으로써 스프링과의 연관관계, 의존성를 최소화할 수 있다.
- 하지만, 동시에 단점이 되며 단점의 요소가 반복적으로 불편하게 만듬.
- jpaTemplate를 통해서 데이터에 접근해야한다.(반복적 코드 상승)
- 스프링의 bean을 이용할 수 없다.
컨테이너 관리형 JPA 구성하기
스프링 컨텍스트
@Bean public LocalContainerEntityManagerFactoryBean entityManagerFactory(DataSource ds, JpaVenderAdapter jpaVenderAdapter) { LocalContainerEntityManagerFactoryBean emfb = new LocalContainerEntityManagerFactoryBean(); emfb.setDataSource(ds); emfb.setJpaVendorAdapter(jpaVenderAdapter); return emfb; }jpaVenderAdapter 프로퍼티는 사용하는 특정 jpa 구현체에 특화된 정보 제공
- EclipseLinkJpaVendorAdapter
- HibernateJpaVendorAdapter
- OpenJpaVendorAdapter
- TopLinkJpaVendorAdapter
HibernateJpaVendorAdapter
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
HibernateJpaVendorAdapter adapter = new HibernateJpaVendorAdapter();
adapter.setDatabase("HSQL");
adapter.setShowSql(true);
adapter.setGeneralDdl(false);
adapter.setDatabasePlatform("org.hibernate.dialect.HSQLDialect");
return adapter;
}
- 컨테이너 관리형 jpa를 구성하면 런타임의 동적인 처리를 퍼시스턴스 객체의 클래스에 조작해야한다.
- Lazy Loading, Eager Loading, 관계등..
- pacakageToScan으로 엔티티 클래스를 간편하게 구별할 수 있다.
- @Entity 어노테이션된 클래스를 지정된 패키지에서 스캔한다.
- persistence.xml에 명시적으로 상세히 선언할 필요가 없다.
11.2.2 JPA 기반 저장소 작성
- 템플릿 기반의 JPA보다 순수 JPA 선호
@Repository
@Transactional
public class JpaSpittleRepository implements SpittleRepository{
@PersistenceContext
private EntityManager em; //EntityManager 주입
public void addSpitter(Spitter spitter) {
em.persist(spitter); //EntityManager 사용
}
}
- @PersistenceContext
- 사용해서 직접 엔티티매니저를 생성할 필요없다.
- EntityManager를 주입하지 않음.
- @PersistenceContext 와 @PersistenceUnit의 차이
- 둘다 스프링 어노테이션이 아니다. JPA 스펙
- 스프링과 엔티티매니저를 이해하고 주입하기 위해선 스프링의 PersistenceAnnotationBeanPostProcessor를 구성 필요
<context:annotation-config/>,<context:componenet-scan/>으로 자동적으로 구성
- @Transctional
- @Repository
PersistenceExceptionTranslationPostProcessor
- JPA, 하이버네이트에 특화된 예외가 발생되도록 하려면 위의 빈 등록
@Bean public BeanPostProcessor peersistenceTranslation() { return new PersistenceExceptionTranslationPostProcessor(); }
11.3 스프링 데이터를 사용한 자동 JPA 저장소
기존의 DB 질의(쿼리)를 하기 위해선 EntityManager와 직접 상호연동해야 했다. 직접연동과 부가적인 코드를 줄이기 위해 spring data jpa는 JpaRepository를 제공한다.
JpaRepository
public interface SpitterRepository extends JpaRepository<Spitter, Long> {}
- spring data jpa 의 JpaRepository를 확장
- 일반적인 퍼시스턴스 작업을 수행하기 위한 여러 방법을 상속한다.
- 스프링 컨텍스트가 생성되는 것처럼, 어플리케이션 시작 타임에 저장소 구현이 이루어진다.
스프링 데이터 JPA 설정
xml config
<jpa:repositories base-package="com.study.spring.db" />
java config
@Configuration
@EnableJpaRepositoriies(basePackage="com.study.spring.db")
public class JpaConfiguration {...}
11.3.1 쿼리 메소드 정의하기
새로운 질의(쿼리) 추가
public interface SpitterRepository extends JpaRepository<Spitter, Long> {
Spitter findByUsername(String username);
}
- 단순 메소드 시그니쳐로 메소드 구현체를 만들기 위한 정보를 스프링 데이터 JPA에 전달.
- 구현체를 만들 시점에, 저장소 인터페이스의 메소드를 검증하고 파싱한다.
findByUsername()
- 동사, 선택 대상, 조건으로 구성
- 동사 : find, 조건 : Username, 선택대상 : Spitter
- 대상은 대부분 무시된다.
- JpaRepository 인터페이스의 타입 파라미터에 의해 정해진다.
Example
List<Spitter> readByFirstnameOrLastname(String first, String last);
대소문자 무시
List<Spitter> readByFirstnameOrLastnameIgnoresCase(String first, String last);
정렬
List<Spitter> readByFirstnameOrLastnameOrderByLastnameAsc(String first, String last);
조건 파트는 AND 또는 OR로 분리
11.3.2 맞춤형 쿼리 선언하기
위의 쿼리메소드의 명명규칙이 지원하지않는 복잡한 쿼리를 작성할 경우는 맞춤형 쿼리를 사용한다.
@Query
@Query("select s from Spitter s where s.email like '%gmail.com'")
List<Spitter> findAllGmailSpitters();
- 구현체가 따로 없어도 @Query 메소드에 있는 쿼리를 실행.
The Java Persistence Query Language (JPQL) is a platform-independent object-oriented query language defined as part of the Java Persistence API (JPA) specification.
JPQL is based on the Hibernate Query Language (HQL), an earlier non-standard query language included in the Hibernate object-relational mapping library. Hibernate and the HQL were created before the JPA specification. As of Hibernate 3 JPQL is a subset of HQL.
11.3.3 맞춤형 기능 혼합
쿼리메소드와 맞춤형 쿼리도 한계가 있다. 그럴때는 EntityManager로 직접 접근하여 질의(쿼리)를 작성할 경우가 있다.
public interface SpitterSweeper {
int eliteSweep();
}
public interface SpitterRepository extends JpaRepository<Spitter, Long>, SpitterSweeper {
Spitter findByUsername(String username);
List<Spitter> findByUsernameOrFullNameLike(String username, String fullName);
}
public class SpitterRepositoryImpl implements SpitterSweeper {
@PersistenceContext
private EntityManager em;
public int eliteSweep() {
String update =
"UPDATE Spitter spitter " +
"SET spitter.status = 'Elite' " +
"WHERE spitter.status = 'Newbie' " +
"AND spitter.id IN (" +
"SELECT s FROM Spitter s WHERE (" +
" SELECT COUNT(spittles) FROM s.spittles spittles) > 10000" +
")";
return em.createQuery(update).executeUpdate();
}
}
@Configuration
@EnableJpaRepositories("com.habuma.spitter.db", repositoryImplementationPostfix="Impl")
public class SpringDataJpaConfig { }